Core Concepts
This chapter describes the fundamental concepts of the Hybridizer: how work is distributed on hardware, the role of kernels and entry points, and how parallelization is expressed.
Work Distribution
The first concept of the Hybridizer is work distribution — the description of how tasks are distributed across hardware execution units. The Hybridizer provides several approaches with different levels of control.
The Work Grid Model
The key element of work distribution is the entry point. An entry point is a method called from a single execution unit that spawns a work grid on a device.
A work grid is composed of:
- Work groups (called "blocks" in CUDA)
- Work items (called "threads" in CUDA)
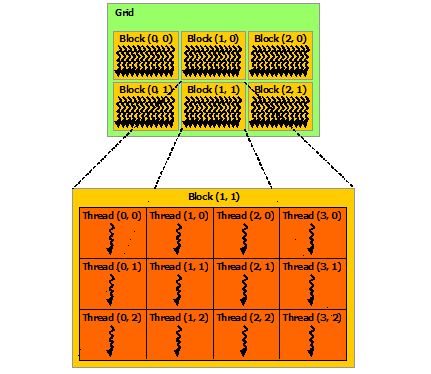
Concept Mapping Across Platforms
| CUDA | OpenCL | Hybridizer Vector |
|---|---|---|
| block | work-group | thread (stack frame) |
| thread | work-item | vector entry (within a vector unit) |
This concept mapping delivers best performance across platforms and enables a single version of the source code.
Explicit Work Distribution
Explicit work distribution reuses the concepts of CUDA. In this case, threadIdx and blockIdx are used to locate the working entity:
[EntryPoint]
public void Square(int count, double[] a, double[] b)
{
for (int k = threadIdx.x + blockDim.x * blockIdx.x;
k < count;
k += blockDim.x * gridDim.x)
{
b[k] = a[k] * a[k];
}
}
- The
blockdimensions map to the multithreading challenge - The
threaddimensions map to the vectorization challenge
This mapping is perfectly aligned with CUDA, allowing the vast majority of code already designed for CUDA to be used without redesign.
Parallel.For Constructs
Similarly to Parallel.For in .NET, the Hybridizer maps the static method to an internal implementation. It may be used within an entry point or a kernel:
[EntryPoint]
public static void RunParallelFor(int[] input, int[] output, int size)
{
Parallel.For(0, size, i => output[i] = input[i] + 1);
}
By default, the loop will iterate over blocks and threads on the CUDA implementation. The third parameter is an action and can also hold local data.
Kernels vs Entry Points
| Concept | Description | Attribute |
|---|---|---|
| Entry Point | Method called from host that spawns a work grid | [EntryPoint] |
| Kernel | Device-side method callable from entry points or other kernels | [Kernel] |
SIMT vs SIMD
- SIMT (Single Instruction, Multiple Threads): Used on GPUs. Each thread has its own instruction pointer but executes in lockstep within a warp (32 threads on NVIDIA).
- SIMD (Single Instruction, Multiple Data): Used on CPUs with AVX/NEON. A single instruction operates on multiple data elements in a wide register.
The Hybridizer abstracts both models, allowing the same algorithm to target either execution model.
Next Steps
- Compilation Pipeline — Understand how code is transformed
- Intrinsics & Builtins — Access hardware-specific features
- Generics, Virtuals, Delegates — Advanced C# features support