CUDA Functions
In CUDA, there are different function types depending on where they execute and where they're called from. Hybridizer maps these concepts to C# attributes.
Function Types
| CUDA | Hybridizer | Executed On | Called From |
|---|---|---|---|
__global__ | [EntryPoint] | Device (GPU) | Host (CPU) |
__device__ | [Kernel] | Device | Device |
__host__ | (none) | Host | Host |
Entry Points (Global Functions)
Entry points are the starting point for GPU execution:
[EntryPoint]
public static void Add(double[] a, double x, int N)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < N)
a[tid] += x;
}
Equivalent CUDA:
__global__ void add(double* a, double x, int N)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < N)
a[tid] += x;
}
Device Functions (Kernels)
Device functions are called from other device code:
[Kernel]
public static double Square(double x)
{
return x * x;
}
[EntryPoint]
public static void SquareArray(double[] a, int N)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < N)
a[tid] = Square(a[tid]); // Calls device function
}
Special Registers
Inside device functions, you have access to special registers:
| Register | Type | Description |
|---|---|---|
threadIdx | dim3 | Thread index in block (x, y, z) |
blockIdx | dim3 | Block index in grid |
blockDim | dim3 | Block dimensions |
gridDim | dim3 | Grid dimensions |
Implicit Parallelism
In CUDA/Hybridizer device code, parallelism is implicit:
- Thread and block allocation is done at kernel launch
- No explicit loop needed (if data fits in grid)
Without Loop (Simple Case)
[EntryPoint]
public static void Add(double[] a, double x, int N)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < N)
a[tid] += x;
}
Memory access pattern (4 threads per block):

With Grid-Stride Loop (General Case)
When N > total threads, use a loop:
[EntryPoint]
public static void Add(double[] a, double x, int N)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int stride = gridDim.x * blockDim.x;
while (tid < N)
{
a[tid] += x;
tid += stride;
}
}

The grid-stride loop pattern is recommended for production code as it handles any array size.
Memory Coalescence
Coalesced access (recommended for GPU):
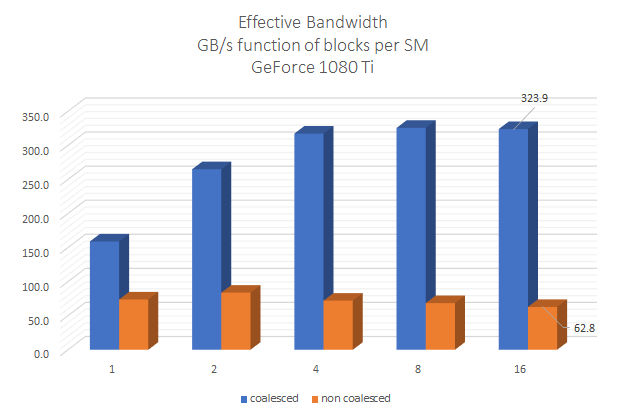
Consecutive threads access consecutive memory addresses. This is efficient on GPU because:
- Memory transactions are 32/64/128 bytes
- Warp threads can share transactions
Sequential access (like OpenMP):

Each thread processes a contiguous chunk. This works well on CPU but poorly on GPU.
Hybridizer infers vectorization from threadIdx usage, making the same code efficient on both platforms.
Synchronization
Block Synchronization
[EntryPoint]
public static void WithSync(float[] data, int N)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
// All threads in block must reach this point
CUDAIntrinsics.SyncThreads();
// Continue execution...
}
Warp Synchronization (CUDA 9+)
// Synchronize specific threads in a warp
CUDAIntrinsics.SyncWarp(0xFFFFFFFF);
Next Steps
- Memory & Profiling — Optimize memory access
- Performance Metrics — Measure kernel efficiency
- Core Concepts — General work distribution